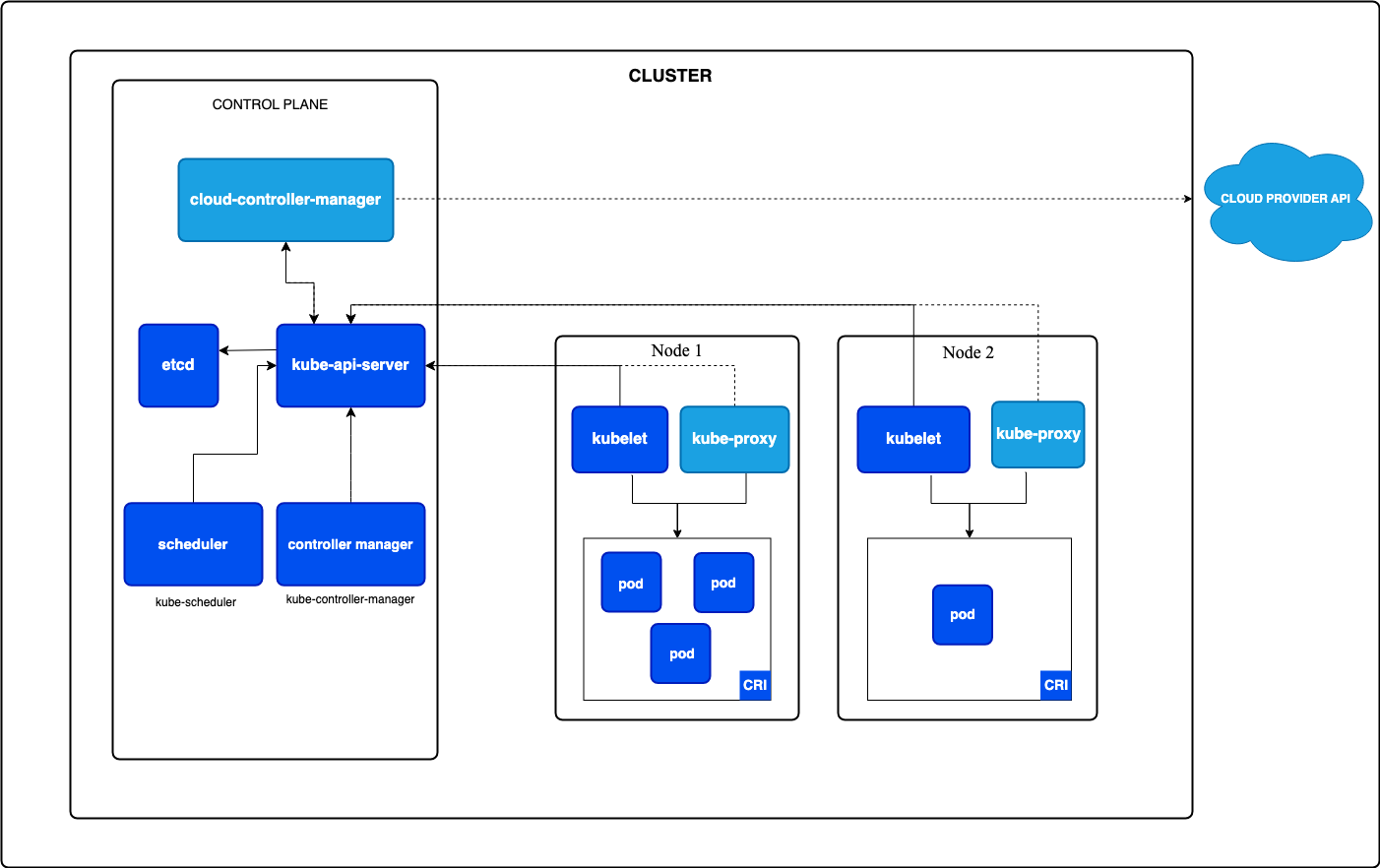
一句话结论
AI Infra 里的 K8S 难点在 GPU device plugin、MIG/MPS、拓扑、Gang 调度、Kueue/Volcano 和 DRA。
复习定位
| 维度 | 内容 |
|---|
| 所属模块 | Kubernetes 核心 |
| 章节类型 | 系统类 |
| 解决问题 | 围绕控制面、调度资源模型、Workload Controller、网络存储、安全多租户、排障和 AI Infra GPU/DRA 建立平台面试答案。 |
| 面试抓手 | 把 K8S 抽象和 GPU 物理资源语义连接起来。 |
AI Infra:GPU / 批调度 / DRA 总览
AI Infra 场景下,Kubernetes 的核心问题从“跑一个无状态服务”扩展为:如何接入 GPU/NPU 等异构硬件,如何让分布式训练一组 Pod 同时拿到资源,如何表达显存、拓扑、MIG、NVLink、NUMA 等复杂约束。
| 方向 | 解决的问题 | 代表机制 |
|---|
| 设备接入 | 让 kubelet 和 scheduler 看到 GPU/NPU | Device Plugin、Extended Resource、DRA |
| 设备共享 | 提高 GPU 利用率 | MIG、MPS、time-slicing、vGPU |
| 拓扑感知 | 减少跨 NUMA、跨 PCIe、跨 NVLink 通信损耗 | Topology Manager、scheduler plugin、DRA attributes |
| 批调度 | 训练任务需要一组 Pod 同时运行 | Gang Scheduling、Volcano、Kueue |
| 队列治理 | 多团队 GPU 配额、公平性和抢占 | Queue、ClusterQueue、PriorityClass、reclaim/borrowing |
GPU Device Plugin:它把 GPU 接进 K8s 的哪一层
Device Plugin 是 kubelet 的节点侧插件机制,用于把 GPU、FPGA、RDMA NIC 等非标准硬件暴露给 Kubernetes。以 NVIDIA GPU 为例,插件通常以 DaemonSet 运行在每个 GPU 节点上,向 kubelet 注册 nvidia.com/gpu 这类扩展资源;kubelet 再把资源数量写入 Node 的 capacity / allocatable,供 scheduler 做整数资源调度。
| 组件 | 职责 | 面试关注点 |
|---|
| Device Plugin Pod | 发现本机设备,维护设备健康状态,通过 gRPC 向 kubelet 注册资源名 | 通常是 DaemonSet,只在有对应硬件的节点运行 |
| kubelet Device Manager | 接收插件注册,维护设备列表,在 Pod 启动前调用 Allocate | Device Plugin 直接对接 kubelet,不直接对接 scheduler |
| Node status | 展示扩展资源总量和可分配量,例如 nvidia.com/gpu: 8 | scheduler 主要看到的是资源名和整数数量 |
| kube-scheduler | 根据 Pod requests/limits 和 Node allocatable 做过滤与打分 | 默认不理解 GPU 型号、显存、NVLink、NUMA 等设备内部属性 |
| Container Runtime | 根据 kubelet 传入的设备信息把 GPU device node、环境变量、mount 注入容器 | 常和 NVIDIA Container Toolkit、CDI 等运行时机制配合 |
Extended Resource 与 Device Plugin
扩展资源是 Kubernetes 资源模型中的“自定义整数资源”,Device Plugin 是最常见的节点侧上报机制。两者关系可以理解为:Device Plugin 负责发现和注册设备,Extended Resource 负责在 Pod spec 和 Node allocatable 中表达可调度数量。
| 环节 | 发生什么 | 关键点 |
|---|
| 资源注册 | Device Plugin 通过 kubelet 注册资源名,例如 nvidia.com/gpu | 资源名必须带域名前缀,避免和原生资源冲突 |
| 库存暴露 | kubelet 把数量写入 Node capacity / allocatable | scheduler 看到的是整数数量,不是每张卡的详细属性 |
| Pod 申请 | Pod 在 resources.limits 中申请,例如 nvidia.com/gpu: 1 | GPU 等扩展资源一般要求 requests 与 limits 相等 |
| 节点选择 | scheduler 根据资源数量过滤节点 | 默认不理解显存、型号、NVLink、NUMA 等设备属性 |
| 设备交付 | Pod 到节点后 kubelet 调用 Device Plugin Allocate | 具体 device node、环境变量、mount 在节点侧注入容器 |
nvidia.com/a100、nvidia.com/v100 也可以通过 Device Plugin 实现,但本质是把“型号”编码进资源名。当还要表达显存、MIG profile、PCIe/SXM、NUMA、NVLink、健康状态时,资源名和 label 组合会迅速爆炸。
Device Plugin 调度与分配链路
- Device Plugin 在节点上发现 GPU,并通过 kubelet 注册资源名,例如
nvidia.com/gpu。
- kubelet 更新 Node
capacity / allocatable。
- 用户 Pod 在
resources.limits 中申请 GPU。
- scheduler 根据 Node allocatable 和 Pod requests/limits 选择节点。
- Pod 绑定到节点后,kubelet 调用 Device Plugin
Allocate。
- Device Plugin 返回 device id、环境变量、mount、device node 或 CDI 信息。
- kubelet 通过 CRI 让容器运行时把设备注入容器。
核心边界:Device Plugin 让 K8s 能看见并交付设备,但默认调度层看到的是资源名和数量,不是完整设备拓扑。
K8s 中 MPS / Time Slicing 的一句话
在 Kubernetes 里使用 MPS 或 Time Slicing,通常不是直接改 kube-scheduler,而是通过 NVIDIA Device Plugin 或 NVIDIA GPU Operator 的配置,把一张物理 GPU 暴露成多个可被 Pod 申请的逻辑 GPU 资源。
scheduler 只看到类似 nvidia.com/gpu.shared: 4 这样的扩展资源数量;底层共享逻辑由 NVIDIA Device Plugin、driver、MPS daemon 或 CUDA/驱动层实现。
K8s 为什么默认不好共享 GPU
Kubernetes 原生资源模型通常把 GPU 当作整数扩展资源。例如 Pod 申请:
resources:
limits:
nvidia.com/gpu: 1
这通常表示这个 Pod 要独占 1 张 GPU。默认调度器只根据 Node 上报的 capacity / allocatable 做整数资源扣减,一张 GPU 被分配后,其他 Pod 不能再申请同一张 GPU。
但开发测试、Notebook、小模型推理、小 batch 服务、低优实验等场景经常用不满一张 GPU,所以 NVIDIA Device Plugin 提供 GPU oversubscription 能力,通过 sharing 配置支持 Time Slicing 和 MPS 两种共享方式。
Time Slicing:把一张 GPU 暴露成多个逻辑 slot
Time Slicing 可以理解为多个 Pod 按时间片轮流使用同一张物理 GPU。它不是把 GPU 硬件切开,而是在软件/驱动层做时间片复用。
| 维度 | 说明 |
|---|
| 资源表达 | 通过 replicas 把每张 nvidia.com/gpu 暴露成多个逻辑 slot |
| 调度视角 | 如果 1 张卡配置 replicas: 4,K8s 会看到 4 个可申请资源;8 张卡会看到 32 个 |
| 隔离能力 | 没有硬件隔离,显存、cache、带宽和 kernel 执行都会互相影响 |
| 适合场景 | 开发测试、Notebook、小实验、小模型推理、内部工具、低优任务 |
| 主要风险 | 一个 Pod 的重 kernel 或高显存占用会影响其他 Pod,P99 延迟可能明显抖动 |
Time Slicing 的关键认知:它让 K8s 能调度更多 Pod 到同一张卡上,但不保证每个 Pod 拿到稳定的 1/N 算力或 1/N 显存。
Time Slicing ConfigMap 示例
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
namespace: gpu-operator
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
renameByDefault: true
failRequestsGreaterThanOne: true
resources:
- name: nvidia.com/gpu
replicas: 4
| 字段 | 含义 | 面试解释 |
|---|
replicas: 4 | 每张物理 GPU 暴露成 4 个共享 slot | 1 张卡上报 4 个资源,8 张卡上报 32 个资源 |
renameByDefault: true | 把共享资源重命名为类似 nvidia.com/gpu.shared | 让用户明确知道自己申请的是共享 GPU,不是独占 GPU |
failRequestsGreaterThanOne: true | 拒绝单个 Pod 一次申请多个共享 slot | 避免用户误以为申请 2 个 slot 就等于拿到 2 张独立 GPU |
Pod 如何申请共享 GPU
如果开启 renameByDefault: true,Pod 侧推荐申请重命名后的共享资源:
apiVersion: v1
kind: Pod
metadata:
name: ts-demo
spec:
containers:
- name: app
image: nvidia/cuda:12.2.0-base-ubuntu22.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu.shared: 1
如果没有开启资源重命名,Pod 仍可能申请 nvidia.com/gpu: 1,但这在语义上容易被误解为独占 GPU。共享资源生产落地时,更推荐使用 nvidia.com/gpu.shared 这类显式资源名。
GPU Operator 如何加载 sharing 配置
如果使用 NVIDIA GPU Operator,常见流程是先创建 ConfigMap,再 patch ClusterPolicy,让 device plugin 读取该配置。
kubectl apply -f time-slicing-config.yaml
kubectl patch clusterpolicies.nvidia.com/cluster-policy \
-n gpu-operator \
--type merge \
-p '{"spec":{"devicePlugin":{"config":{"name":"time-slicing-config","default":"any"}}}}'
- 管理员创建 sharing ConfigMap。
- GPU Operator 或 NVIDIA Device Plugin 加载该配置。
- Device Plugin 重新向 kubelet 注册扩展资源数量。
- kubelet 更新 Node
capacity / allocatable。
- scheduler 按新的逻辑资源数量调度 Pod。
注意:不同 GPU Operator / Device Plugin 版本的字段和 patch 命令可能略有差异,但核心模式都是 ConfigMap → Device Plugin → kubelet 上报资源 → Pod 申请扩展资源。
MPS:多 CUDA 进程并发共享 GPU
MPS 是 NVIDIA Multi-Process Service。它让多个 CUDA 进程通过 MPS control daemon 共享同一张 GPU,减少上下文切换开销,并提升小 kernel、多进程推理等场景的并发执行效率。
| 维度 | Time Slicing | MPS |
|---|
| 共享方式 | 多个 workload 按时间片轮流用 GPU | 多个 CUDA 进程通过 MPS daemon 并发提交 work |
| 实现直觉 | 轮流用 | 一起提交 CUDA work |
| 隔离能力 | 弱,主要是时间复用 | 比 Time Slicing 稍强,可做一定计算/显存资源限制 |
| 适合场景 | 开发测试、Notebook、低优任务、小推理 | 同团队可信任务、小 kernel、多 CUDA 进程推理 |
| 不适合场景 | 强 SLA、强隔离、多租户不可信任务 | 强硬隔离、大模型训练、显存不可控、不可信用户 |
面试时要强调:MPS 仍然不是 MIG 那种硬件级隔离。它能改善并发和一定程度资源控制,但故障、显存、cache、带宽和性能干扰仍然可能跨 Pod 传播。
MPS ConfigMap 示例
apiVersion: v1
kind: ConfigMap
metadata:
name: mps-config
namespace: gpu-operator
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
mps:
renameByDefault: true
failRequestsGreaterThanOne: true
resources:
- name: nvidia.com/gpu
replicas: 4
这个配置的含义是:每张 GPU 通过 MPS 方式暴露成 4 个共享 slot。Pod 侧仍然通过 resources.limits 申请共享 GPU,例如 nvidia.com/gpu.shared: 1。具体资源名是否重命名取决于 renameByDefault 和当前 device plugin 版本。
生产使用注意事项
| 问题 | 说明 | 工程建议 |
|---|
| K8s 不理解性能隔离 | scheduler 只看到逻辑资源数量,不知道每个 slot 的真实算力、显存、带宽 | 不要把 replicas: 8 理解为稳定 1/8 GPU |
| 显存互相影响 | Time Slicing 下多个 Pod 共享整张卡显存,单个 Pod 高显存占用可能导致其他 Pod OOM | 按 workload profiling 设置 replicas,限制不可信任务 |
| 延迟抖动 | 重 kernel、长任务、上下文切换和带宽争用会拉高 P99 | 强 SLA 在线服务优先用独占 GPU、MIG,或只让同类服务共享 |
| 监控归因困难 | 启用 Time Slicing 后,DCGM-Exporter 对 container 维度 GPU metrics 的归因能力可能受限 | 补充应用侧指标、队列指标、Pod 级吞吐和延迟观测 |
| 过度超卖 | replicas 配太大容易造成显存爆、上下文切换严重、P99 暴涨 | 从 2/4 这类保守值灰度,按业务曲线逐步调参 |
MIG / MPS / Time Slicing / vGPU 对比
| 机制 | 隔离粒度 | 优点 | 风险 | 典型场景 |
|---|
| MIG | 硬件级 GPU 分区 | 隔离强,profile 清晰 | 切分形态固定,资源碎片 | 多租户推理、强隔离生产服务 |
| MPS | 进程级共享 | 提升小任务并发利用率,可做一定资源控制 | 不是硬隔离,干扰和故障影响复杂 | 可信团队内多进程推理、小 kernel 任务 |
| Time Slicing | 时间片共享 | 部署简单,兼容性好,适合轻量任务 | 显存共享,QoS 不稳定,P99 抖动明显 | Notebook、开发测试、低优实验、小推理 |
| vGPU | 虚拟化切分 | 适合云化售卖和多租户 | 依赖厂商方案和授权 | 云桌面、云 GPU、多租户售卖 |
批调度:Gang、Kueue、Volcano
分布式训练通常需要 worker、parameter server、launcher 等一组 Pod 同时运行。如果只按单 Pod 调度,可能出现部分 worker 占住 GPU,剩余 worker 长期 Pending,导致资源浪费。Gang Scheduling 要求一组 Pod 要么一起拿到资源,要么一起等待。
| 机制 | 定位 | 面试回答 |
|---|
| Gang Scheduling | 调度语义 | 一组 Pod 满足最小可运行数量后再整体放行 |
| Volcano | 批调度系统 | 提供 Queue、PodGroup、Gang、DRF、公平调度等能力 |
| Kueue | K8s 原生批任务准入 | 更偏资源准入和队列治理,与 Job、RayJob、训练 Operator 集成 |
| Permit 插件 | Scheduling Framework 扩展点 | 可让 Pod 在绑定前等待同组 Pod 凑齐 |
DRA 是什么
DRA 是 Dynamic Resource Allocation,面向 GPU、DPU、FPGA、NIC 等设备的新一代动态资源分配 API。它的目标不是替代所有 Device Plugin 场景,而是解决传统扩展资源在复杂异构设备上的表达能力不足。
| DRA 对象 | 类比 | 作用 |
|---|
| DeviceClass | StorageClass | 管理员定义一类可申请设备及选择规则 |
| ResourceClaim | PVC | 用户声明自己需要什么设备 |
| ResourceClaimTemplate | volumeClaimTemplates | 为每个 Pod 自动生成相似但独立的 claim |
| ResourceSlice | 设备库存分片 | DRA driver 发布设备列表、属性、容量、拓扑和可访问节点 |
| Pod resourceClaims | Pod 引用 PVC | Pod 声明要使用哪些 ResourceClaim |
DRA 与传统资源模型的边界
DRA 不是把 resources.requests 简单增强成更复杂的字段,而是引入 resource.k8s.io API,用 ResourceClaim 表达需求、用 ResourceSlice 发布设备库存、用 DeviceClass 抽象设备类别。传统 Extended Resource 适合“资源名 + 整数数量”,DRA 更适合“设备属性 + 容量 + 拓扑 + 共享关系”。
| 维度 | Device Plugin / Extended Resource | DRA |
|---|
| 资源表达 | 资源名 + 整数数量 | 结构化设备属性、容量、拓扑、选择条件 |
| 调度可见性 | scheduler 主要看到数量 | scheduler 可基于 ResourceSlice 做设备级匹配 |
| 适合场景 | 同质 GPU、简单整卡分配 | 异构 GPU/NPU/DPU、MIG、拓扑、共享设备 |
| 复杂度 | 简单成熟,生态广 | 能力强,但依赖 API 版本和 DRA driver 生态 |
ResourceSlice 深入理解
ResourceSlice 是 DRA 的设备库存分片。它通常由 DRA driver 自动创建和维护,用户和平台管理员一般不手写。它把设备的结构化信息发布给 API Server,让 scheduler 能基于设备属性、容量和拓扑做匹配。
| 字段/概念 | 含义 | 为什么重要 |
|---|
| driver | 哪个 DRA driver 管理这批设备 | 避免不同厂商/驱动资源混淆 |
| pool | 资源池名称、generation、slice 数量 | 帮助 scheduler 判断同一资源池的库存版本 |
| nodeName / nodeSelector | 这些设备在哪些节点可用 | 设备必须和 Pod 调度节点匹配 |
| devices | 设备列表 | 可以表达每个 GPU/NPU/NIC 的名称、属性、容量 |
| attributes | 结构化属性 | 型号、厂商、NUMA、PCIe、NVLink、MIG profile 等 |
| capacity | 设备容量 | 显存、队列数、带宽等可被选择或分配 |
大集群中会有很多 ResourceSlice,这是预期设计。它避免把大量设备细节全部塞进 Node status,也避免用 nvidia.com/a100、nvidia.com/a100-80g-sxm-numa0 这类资源名无限膨胀。
CEL 表达式在 DRA 中的作用
CEL 是 Common Expression Language,一种安全、可嵌入的表达式语言。DRA 可以用 CEL 对 ResourceSlice 中的设备属性做过滤,例如选择 A100、显存至少 80Gi、同 NUMA 或带特定 NVLink fabric 的设备。
selectors:
- cel:
expression: "device.attributes['model'].string == 'A100' && device.capacity['memory'].quantity >= quantity('80Gi')"
面试回答要点:CEL 的价值是把“申请某个资源名”升级为“基于结构化设备属性做查询”。
DRA driver 是什么
DRA driver 是 Kubernetes 侧的设备资源驱动,不是 Linux kernel driver,也不是 CUDA/NPU runtime 本身。它负责把真实硬件接入 DRA API:一边向 API Server 发布设备库存,一边在 Pod 落到节点后配合 kubelet 准备并交付设备。
| 职责 | 具体动作 | 对应对象/接口 |
|---|
| 设备发现 | 发现 GPU、NPU、DPU、FPGA、NIC 等设备,读取型号、显存、拓扑、健康状态 | 厂商 runtime、节点 agent |
| 库存发布 | 把设备列表、属性、容量、资源池信息写入 API Server | ResourceSlice |
| 分配协作 | 让 scheduler 能基于 ResourceClaim 选择具体设备,并把分配结果写入 claim 状态 | scheduler + ResourceClaim.status |
| 设备准备 | Pod 绑定后在目标节点上准备设备,例如 CDI、device node、环境变量、mount、MIG/VF 配置 | kubelet 调用 driver 的 prepare/unprepare |
| 回收与健康 | Pod 结束后清理设备状态,设备故障时更新可用性 | driver controller / node plugin |
一句话:Kubernetes 提供 DRA 框架和 API,DRA driver 负责把某类真实硬件翻译成 Kubernetes 能理解和交付的资源。
DRA 与 Device Plugin 是否冲突
| 模式 | 是否可行 | 说明 |
|---|
| 纯 Device Plugin | 可行 | 成熟稳定,适合同质整卡资源 |
| 纯 DRA | 可行 | 适合新集群或强异构设备,但依赖 driver 生态 |
| 按 node pool 共存 | 推荐 | 一部分节点继续 DP,一部分节点灰度 DRA |
| 按设备类型共存 | 可行 | GPU 用 DP,DPU/特殊 NIC 用 DRA,或反过来 |
| 同一物理设备同时暴露 | 不推荐 | 可能导致双重分配和资源状态不一致 |
DRA 排障路径
# 1. 看 DRA API 是否存在
kubectl api-resources | grep resource.k8s.io
# 2. 看是否有设备库存
kubectl get resourceslices -A
# 3. 看平台暴露了哪些设备类别
kubectl get deviceclasses
# 4. 看具体 claim 的分配状态
kubectl describe resourceclaim <claim-name>
# 5. 看 driver 组件是否运行
kubectl get pods -A | grep -i dra
如果 ResourceClaim 长期未分配,重点检查 DeviceClass 是否存在、ResourceSlice 是否发布、CEL selector 是否过严、节点可访问性是否满足、driver controller 和 node plugin 是否正常。
面试高频追问:默认展示版
| 问题 | 回答要点 | 可继续展开 |
|---|
| ResourceSlice 是谁创建的? | 通常由 DRA driver 自动创建和维护,用户一般不手写 | driver 根据节点、资源池、设备类型和更新粒度做分片 |
| 大集群会不会有很多 ResourceSlice? | 会,而且这是预期设计;目的是避免 Node 对象膨胀和资源名爆炸 | 代价是 API Server / scheduler watch 对象更多,需要控制分片和更新频率 |
| DRA 和 Device Plugin 冲突吗? | 集群层面可以共存,同一物理设备不能双重暴露 | 推荐按 node pool、设备类型或灰度资源池隔离 |
| K8s 中怎么使用 MPS / Time Slicing? | 通过 NVIDIA Device Plugin / GPU Operator 配置 sharing 和 replicas,把物理 GPU 暴露成多个逻辑 slot | ConfigMap、nvidia.com/gpu.shared、隔离边界、监控归因 |
nvidia.com/a100 已能表达卡型,DRA 价值在哪里? | 资源名编码只能解决简单分类,DRA 可表达结构化属性、容量、拓扑和共享关系 | 显存、NVLink、NUMA、MIG profile、健康状态都适合放进 ResourceSlice |
| DRA driver 和 Linux driver 是一回事吗? | 不是。Linux driver / CUDA / NPU runtime 管底层硬件,DRA driver 管 Kubernetes 资源发现、库存发布和设备交付 | 面试中要说清楚 controller、node plugin、prepare/unprepare 的边界 |
| 国产 GPU/NPU 是否有 DRA driver? | 公开成熟度要谨慎判断;多数生态更常见的是 Device Plugin、Operator、vGPU 或 HAMi 等方案 | 判断真 DRA 看是否使用 resource.k8s.io、ResourceSlice、DeviceClass、ResourceClaim |
AI Infra GPU / DRA 高频问答
本模块的问答按“概念 → 作用 → 链路/排查 → 面试口径”组织,避免只背一段结论。
Q: GPU Device Plugin 和普通调度有什么关系?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. Device Plugin 的概念
Device Plugin 是节点侧插件,负责发现 GPU/NPU 等设备,并通过 gRPC 向 kubelet 注册扩展资源。
2. 对 scheduler 的作用
kubelet 会把扩展资源数量写入 Node capacity/allocatable,scheduler 根据 Pod limits 和 Node allocatable 做过滤。
3. 对 kubelet 的作用
Pod 绑定到节点后,kubelet 调用 Device Plugin Allocate,拿到 device id、环境变量、mount、CDI 等设备交付信息。
4. 边界
Device Plugin 让 K8s 能看到和交付设备,但默认调度器主要看到资源名和数量,不理解完整显存、拓扑和共享关系。
面试口径:Device Plugin 负责设备发现和节点侧交付,scheduler 只基于 kubelet 上报的扩展资源数量做普通调度。
Q: Kubernetes 中如何使用 MPS 和 Time Slicing 共享 GPU?
回答思路:先说不是改 scheduler,再说 Device Plugin / GPU Operator 的资源上报方式,最后补充两者区别和生产风险。
1. 落地方式
通常通过 NVIDIA Device Plugin 或 GPU Operator 配置 sharing。管理员在 ConfigMap 中配置 sharing.timeSlicing 或 sharing.mps,并为 nvidia.com/gpu 设置 replicas。
2. K8s 看到什么
如果一张 GPU 配成 replicas: 4,kubelet 上报后 scheduler 会看到 4 个逻辑 GPU slot;如果启用 renameByDefault,Pod 通常申请 nvidia.com/gpu.shared: 1。
3. 两者区别
Time Slicing 是多个 Pod 按时间片轮流使用 GPU,配置简单但隔离弱;MPS 是多个 CUDA 进程通过 MPS daemon 并发共享 GPU,能减少上下文切换并做一定资源控制,但仍不是硬隔离。
4. 生产注意
共享 GPU 不能当作 MIG。要关注显存 OOM、P99 抖动、DCGM 监控归因限制、过度超卖和不同 workload 之间的干扰。
面试口径:K8s 调度的是 Device Plugin 上报的逻辑 GPU slot,Time Slicing 负责轮流用,MPS 负责多 CUDA 进程并发共享,二者都不等于硬件级隔离。
Q: nvidia.com/a100、nvidia.com/v100 不也是 Device Plugin 实现的吗?那 DRA 价值在哪里?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 它确实可以做到
Device Plugin 可以把不同卡型编码成不同扩展资源名,例如 nvidia.com/a100、nvidia.com/v100。
2. 资源名编码的问题
当还要表达显存大小、MIG profile、NUMA、NVLink、PCIe/SXM、健康状态、共享关系时,资源名和 label 会组合爆炸。
3. DRA 的价值
DRA 用 ResourceSlice 发布结构化设备属性,用 ResourceClaim 和 CEL 表达需求,让 scheduler 做设备级匹配。
4. 适用边界
简单同质整卡分配继续用 Device Plugin 就够;复杂异构、共享、拓扑感知场景更适合 DRA。
面试口径:Device Plugin 能表达简单卡型,DRA 的价值是结构化表达设备属性、容量、拓扑和共享关系。
Q: ResourceSlice 是谁创建的?大集群会不会很多?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 谁创建
ResourceSlice 通常由 DRA driver 的 controller 或节点组件自动创建和维护,用户一般不手写。
2. 表达什么
它表达设备库存分片,包括 driver、pool、可访问节点、设备列表、attributes、capacity 等结构化信息。
3. 大集群数量
大集群会有很多 ResourceSlice,这是设计预期,用来避免把大量设备细节塞进 Node status。
4. 治理点
需要控制分片粒度、更新频率、对象大小和 watch 压力,否则会给 API Server 和 scheduler 带来额外负担。
面试口径:ResourceSlice 由 DRA driver 维护,大集群很多是正常的,关键是控制分片和更新频率。
Q: CEL 表达式在 DRA 中怎么理解?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. CEL 是什么
CEL 是 Common Expression Language,一种安全可嵌入的表达式语言,适合在 Kubernetes API 中做轻量条件判断。
2. 在 DRA 中的作用
DRA 可以用 CEL 基于设备属性过滤候选设备,例如型号、显存、NUMA、NVLink fabric、厂商等。
3. 和资源名的区别
传统方式是“申请某个资源名”,CEL 是“查询满足结构化条件的设备”,表达能力更强。
4. 注意点
表达式过复杂或条件过严会导致匹配失败,生产上要配合 DeviceClass、ResourceSlice 和调度日志排查。
面试口径:CEL 让 DRA 从申请固定资源名升级为按结构化设备属性做筛选。
Q: DRA 和 Device Plugin 能不能同时使用?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 集群层面
可以共存,例如一批节点继续使用 Device Plugin,另一批节点灰度 DRA。
2. 设备层面
同一块物理设备不建议同时由 DP 和 DRA 暴露,否则可能出现双重分配和状态不一致。
3. 推荐方式
按 node pool、设备类型、业务队列或灰度资源池隔离,逐步验证 DRA 的调度、prepare、回收和监控。
4. 迁移策略
先低风险业务灰度,再迁移复杂异构设备;保留回滚路径和资源命名隔离。
面试口径:DP 和 DRA 可以共存,但同一物理设备不能双重暴露,推荐按节点池或设备类型隔离迁移。
Q: DRA driver 是什么?如何获取?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 概念
DRA driver 是 Kubernetes 侧设备资源驱动,不是 Linux kernel driver,也不是 CUDA/NPU runtime。
2. 作用
它负责发现设备、发布 ResourceSlice、协助 ResourceClaim 分配,并在 Pod 落到节点后 prepare/unprepare 设备。
3. 组成
通常包含 controller、node plugin、CRD/Helm chart/Operator 等组件,具体形态由厂商或社区实现。
4. 获取方式
一般来自硬件厂商、云平台或社区项目;是否成熟要看它是否支持 resource.k8s.io API、ResourceSlice、DeviceClass、ResourceClaim 和 kubelet prepare/unprepare。
面试口径:DRA driver 把真实硬件翻译成 Kubernetes DRA 资源,来源通常是厂商或社区组件。
Q: 国产 GPU/NPU 厂商有没有 DRA driver,面试怎么回答?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 谨慎态度
不要武断说都有或都没有,DRA 生态仍在演进,公开成熟度需要看具体厂商、版本和项目。
2. 常见现状
很多国产 GPU/NPU 生态更常见的是 Device Plugin、Operator、vGPU、HAMi 或厂商自定义调度方案。
3. 判断标准
看是否使用 resource.k8s.io API,是否发布 ResourceSlice、DeviceClass、ResourceClaim,是否支持 kubelet prepare/unprepare。
4. 面试补充
可以说“如果没有成熟 DRA driver,生产上通常先用 Device Plugin/Operator 接入,再通过 scheduler plugin、label、拓扑信息做增强”。
面试口径:国产 GPU/NPU 是否有成熟 DRA driver 要按公开实现判断,不能泛化;判断标准是是否完整使用 DRA API 和设备交付链路。
Q: 如何从 Device Plugin 平滑迁移到 DRA?
回答思路:先说概念和作用,再按链路或排查维度展开,最后给一句面试总结。
1. 先隔离资源池
不要在同一批物理设备上同时开放 DP 和 DRA,先建设独立 node pool 或灰度队列。
2. 部署 DRA 组件
部署 DRA driver,确认 DeviceClass、ResourceSlice、ResourceClaim 等 API 对象正常生成和更新。
3. 灰度业务
选择少量训练任务通过 ResourceClaim 接入,验证调度、prepare、容器注入、监控、回收和失败恢复。
4. 逐步迁移
按设备类型、业务队列或团队逐步迁移,保留 DP 回滚路径,并防止双重分配。
面试口径:迁移 DRA 要隔离节点池、灰度验证资源申请和设备交付链路,不能一上来混用同一批设备。
关联模块
GPU 硬件与资源共享:提供 SM、HBM、NVLink、MIG/MPS、利用率诊断等底层直觉。LLM 推理系统:提供 Prefill/Decode、KV Cache、Serving Engine 和推理优化语境。Kubernetes 核心:提供调度、资源模型、控制器和扩展机制。分布式训练 / 调度与集群:提供多卡通信、队列、公平性、拓扑和容错背景。