一句话结论
Roofline Model 是性能预测的理论基线:用算力 π、带宽 β 和模型的计算强度 I 三个量,给出模型在某硬件平台上的理论性能上限 $P = \min(\pi, \beta \cdot I)$。
复习定位
| 维度 | 内容 |
|---|
| 所属模块 | 性能预测与建模 |
| 章节类型 | 机制类(含公式) |
| 解决问题 | 在没有跑实验的前提下,先估出"模型在某张卡上能跑多快"的上界,作为容量规划、调度选机器、瓶颈定位的第一性参考。 |
| 面试抓手 | 算力、带宽、计算强度三个量;Compute-Bound vs Memory-Bound 判定;VGG16 vs MobileNet 在 1080Ti 上的对比。 |
| 出处 | 整理自 知乎:Roofline Model 介绍。 |
阅读路径
- 先记住一句话结论:Roofline 给的是性能上界,不是实际表现。
- 看两组指标:平台侧(π、β、I_max)和模型侧(计算量、访存量、I)。
- 用 VGG16 / MobileNet 在 1080Ti 上的对比,把"为什么小模型在大卡上跑不出加速比"这个反直觉结论建起来。
- 最后看常见误区,避免把 Roofline 当成实际性能。
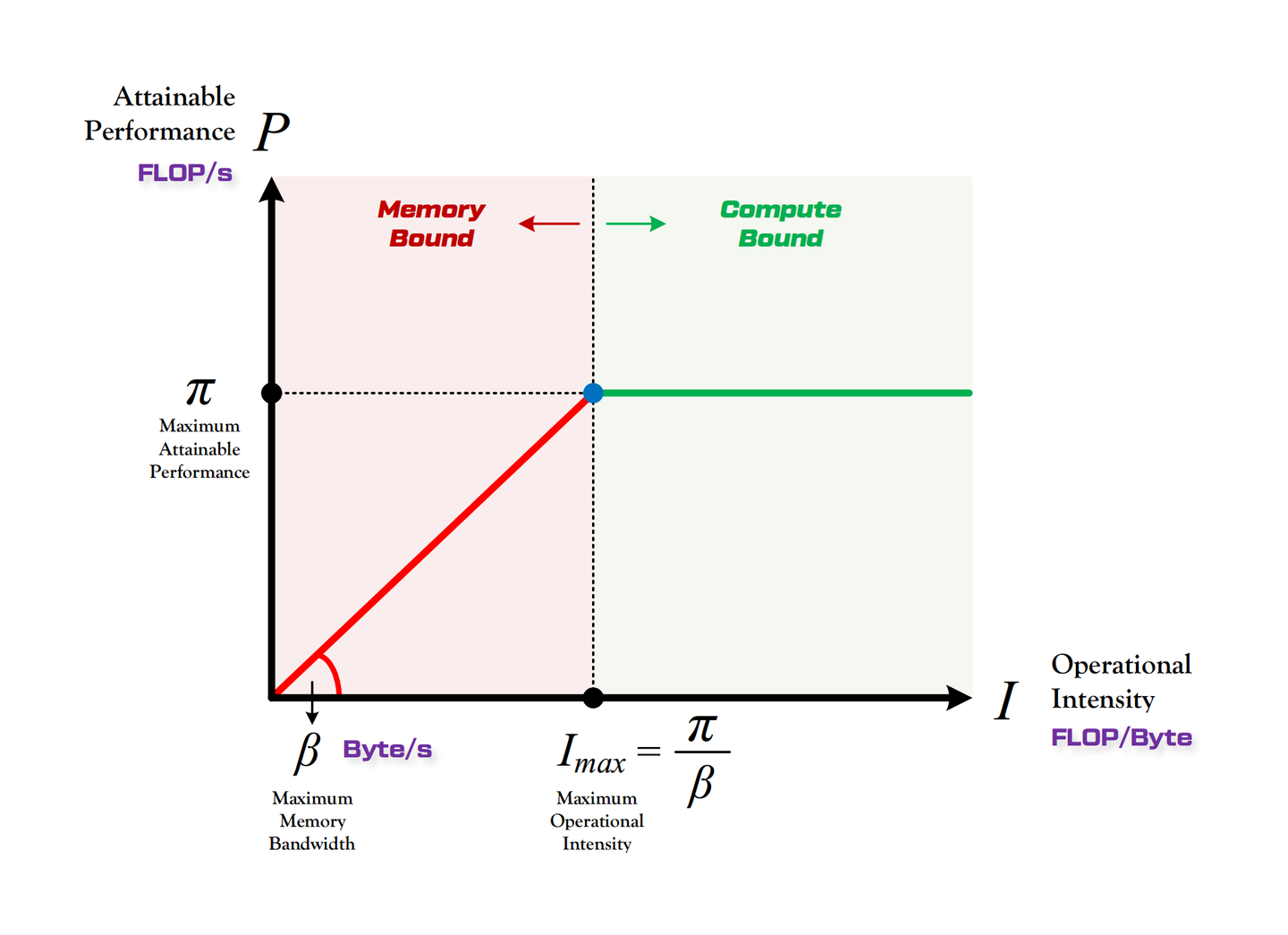
① 计算平台的两个指标:算力 π 与带宽 β
| 指标 | 含义 | 单位 | 面试一句话 |
|---|
| 算力 π | 计算平台每秒能做的浮点运算数(性能上限) | FLOP/s | "屋顶的高度" |
| 带宽 β | 计算平台每秒能完成的内存交换量(带宽上限) | Byte/s | "房檐的斜率" |
| 计算强度上限 Imax | π / β,单位内存交换最多能撑多少次计算 | FLOPs/Byte | "屋顶和房檐的交点" |
$$I_{max} = \frac{\pi}{\beta}$$
注意:这里"内存"是广义的——CPU 平台上是主存,GPU 平台上是显存(HBM)。π / β 都是峰值,不是平均。
② 模型的两个指标:计算量与访存量
| 指标 | 含义 | 单位 | 对应复杂度 |
|---|
| 计算量 FLOPs | 单次前向传播的浮点运算总数 | FLOPs | 时间复杂度 |
| 访存量 Bytes | 单次前向传播的内存交换总量(理想情况下 = 权重内存 + 特征图内存) | Byte | 空间复杂度 |
| 计算强度 I | 计算量 ÷ 访存量,每搬 1 Byte 数据能做多少次浮点运算 | FLOPs/Byte | 数据复用率 |
| 理论性能 P | 模型在该平台上的每秒浮点运算次数(Roofline 的输出) | FLOP/s | 性能上界 |
卷积层的两个常用公式(M = 输出特征图边长,K = 卷积核边长,C 为通道数):
$$\text{Conv Time Complexity} = M^2 \cdot K^2 \cdot C_{in} \cdot C_{out} \quad (\text{FLOPs})$$
$$\text{Conv Space Complexity} = (K^2 \cdot C_{in} \cdot C_{out} + M^2 \cdot C_{out}) \cdot 4 \quad (\text{Bytes})$$
访存量乘 4 是因为 float32 占 4 字节。I = 计算量 / 访存量,I 越大说明数据复用率越高,越不容易卡在内存上。
③ Roofline Model:把两组指标拼起来
Roofline 解决的核心问题:计算量为 A、访存量为 B 的模型,在算力为 C、带宽为 D 的平台上,理论性能上界是多少?用一个分段函数表达:
$$P = \begin{cases} \beta \cdot I, & I < I_{max} \quad \textbf{(Memory-Bound)} \\[1.2ex] \pi, & I \geq I_{max} \quad \textbf{(Compute-Bound)} \end{cases}$$
| 区域 | 判定 | 瓶颈在哪 | 优化方向 |
|---|
| Compute-Bound(屋顶) | I ≥ Imax | 算力 π 限死了 P | 低精度(FP16/INT8)、TensorCore、提高 SM 利用率;这种状态其实是好的,说明算力被吃满了 |
| Memory-Bound(房檐) | I < Imax | 带宽 β 限死了 P | kernel fusion 减少访存、量化压缩权重、提高 batch 提高数据复用、用 cache/SRAM |
本质:模型的 I 和平台的 Imax 谁大谁小,决定了你优化的发力点。Imax 是平台的属性,I 是模型的属性,两者无关——这就是为什么"同一个模型换一张卡,瓶颈类型可能完全不同"。
怎么读 Roofline 图
| 图上元素 | 含义 | 面试解释 |
|---|
| X 轴:Arithmetic Intensity | FLOPs / Byte | 每搬 1 Byte 数据能做多少计算,越高说明数据复用越好 |
| Y 轴:Performance | FLOPs/s | 实际达到的计算吞吐 |
| Memory Roof | Bandwidth × Arithmetic Intensity | 斜线区域说明性能被内存带宽限制 |
| Compute Roof | Peak FLOPs/s | 水平线区域说明性能被计算峰值限制 |
| Ridge Point | Peak FLOPs/s ÷ Peak Bandwidth | 低于它偏 memory-bound,高于它才可能 compute-bound |
Roofline 不是告诉你真实耗时一定是多少,而是告诉你理论上限在哪里,以及优化应该朝哪个方向走。
一个数字例子
假设 GPU 峰值算力是 100 TFLOPS,显存带宽是 2 TB/s,那么 ridge point = 50 FLOPs/Byte。
| Kernel | 算术强度 | 带宽屋顶 | 最终上限 | 判断 |
|---|
| A | 5 FLOPs/Byte | 10 TFLOPS | min(100, 10)=10 | memory-bound |
| B | 100 FLOPs/Byte | 200 TFLOPS | min(100, 200)=100 | compute-bound |
面试口径:低算术强度的 kernel 即使 GPU 峰值算力很高也跑不满,因为数据搬运先撞到 memory roof。
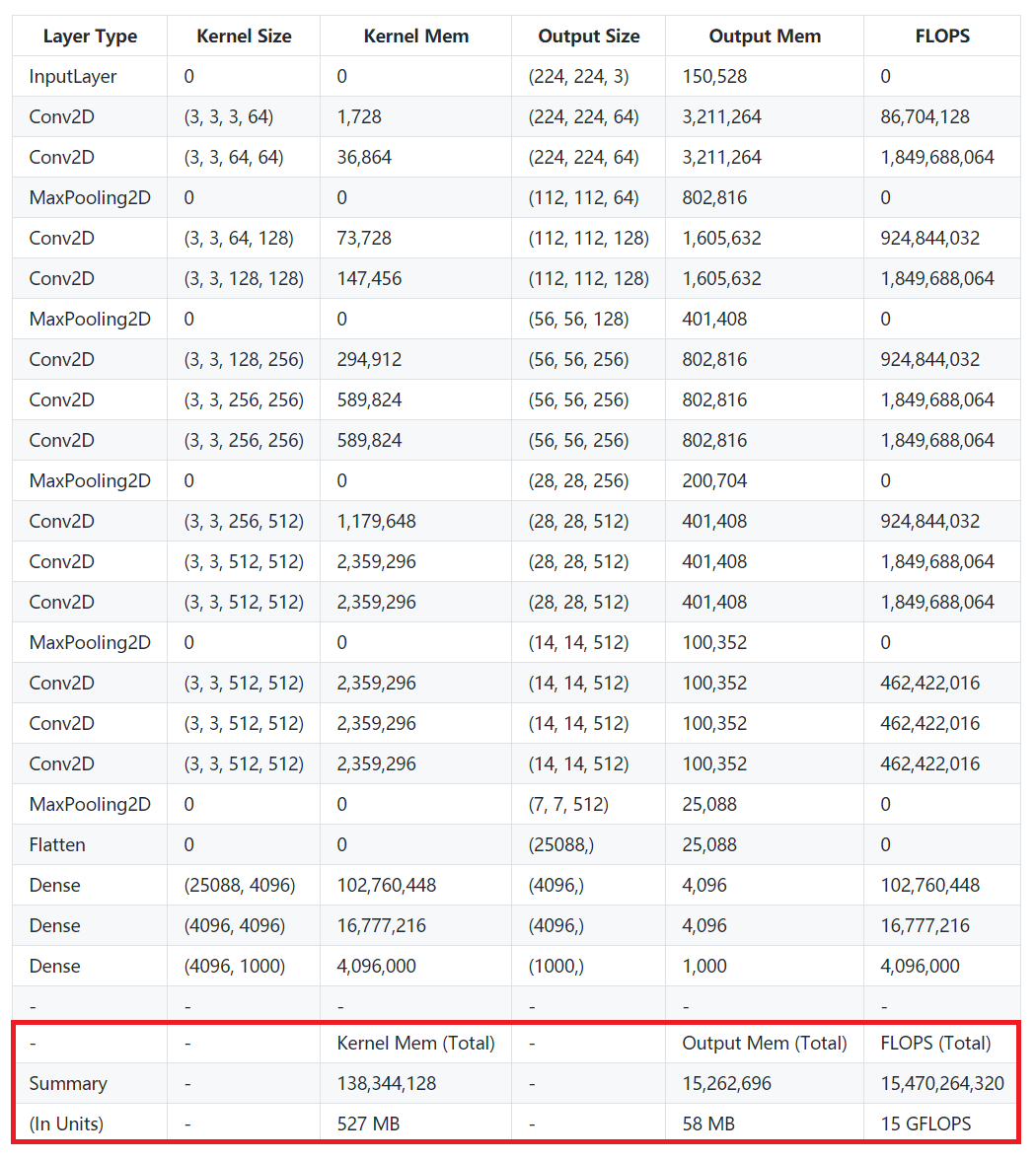
④ 实例分析:VGG16 vs MobileNet 在 1080Ti 上
VGG16
- 计算量 ≈ 15 GFLOPs(前向)
- 访存量 ≈ 600 MB(Kernel Mem + Output Mem,乘 4)
- 计算强度 IV ≈ 25 FLOPs/Byte
VGG 是计算强度登峰造极的模型,简约不简单。如果把顶端两个全连接层(占 80% 参数)换成 GAP,计算强度还能再翻 4 倍以上。
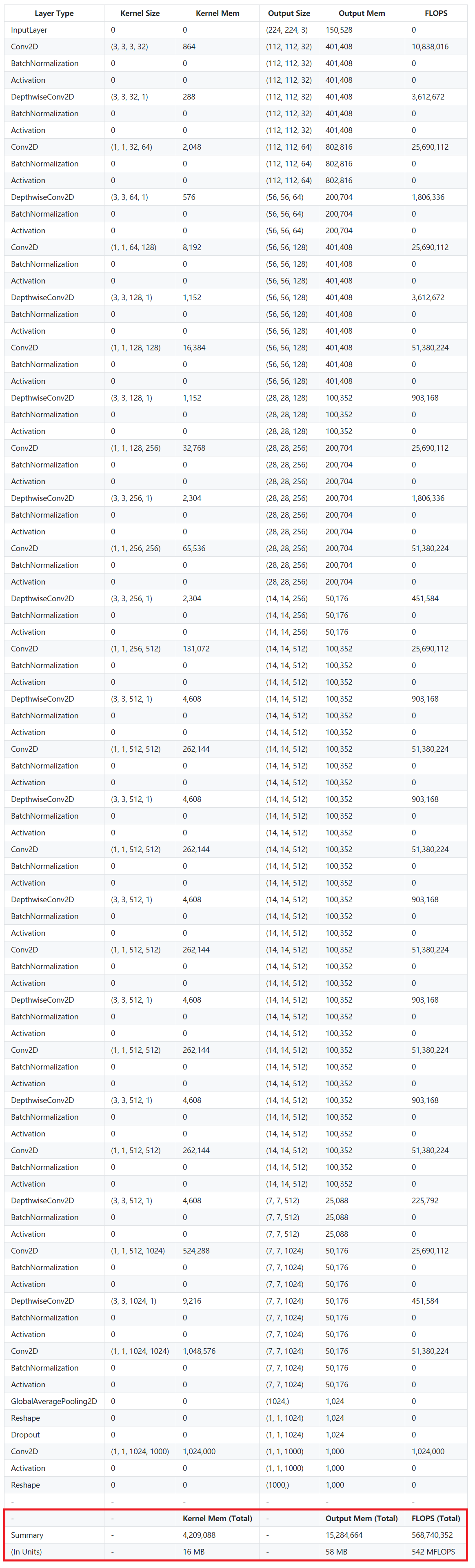
MobileNet
- 计算量 ≈ 0.5 GFLOPs(VGG16 的 1/30)
- 访存量 ≈ 74 MB(VGG16 的 1/8)
- 计算强度 IM ≈ 7 FLOPs/Byte
FLOPs 降得比访存量更快,所以 I 反而下降了——这就是 DW + PW 这种"轻量化"算子的代价。
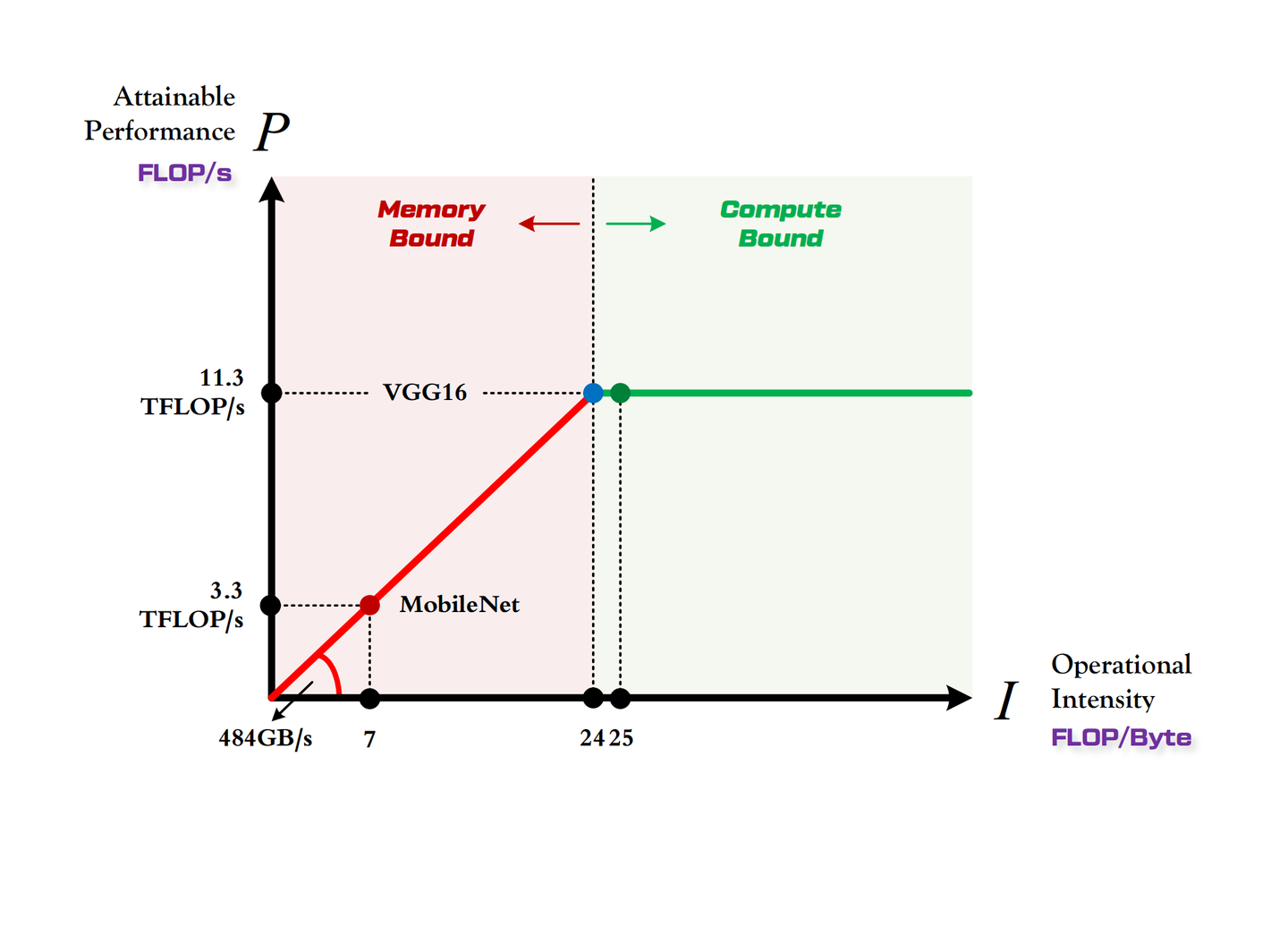
放进 1080Ti 的 Roofline
| 项 | 数值 |
|---|
| 1080Ti 算力 π | 11.3 TFLOP/s |
| 1080Ti 带宽 β | 484 GB/s |
| 1080Ti 计算强度上限 Imax | ≈ 24 FLOPs/Byte |
| VGG16 的 IV | ≈ 25 → 刚好越过 Imax,Compute-Bound |
| MobileNet 的 IM | ≈ 7 → 远低于 Imax,Memory-Bound |
反直觉结论:MobileNet 的计算量只有 VGG 的 1/30,但在 1080Ti 上的实际加速大约只有 10 倍。原因是 MobileNet 卡在带宽上(PM ≈ β · IM = 3.3 TFLOP/s),而 VGG 吃满了 1080Ti 的全部算力(PV = π = 11.3 TFLOP/s)。小模型在大卡上跑不满。
⑤ 工程含义:什么模型该跑在什么平台
| 场景 | 平台特征 | 合适的模型 | 原因 |
|---|
| 大卡训练(A100/H100/1080Ti) | π 高、β 高,Imax 通常 10-100 | VGG / 大型 Transformer | 计算强度高,能站到屋顶;MobileNet 这种放上来反而是浪费带宽 |
| 嵌入式 / 端侧 (TPU Edge / 手机 NPU) | π 低、β 也低,Imax 通常 < 5 | MobileNet / 量化小模型 | IM = 7 在端侧已经能站到屋顶,反而能吃满算力,准确率只下降 1% |
| 大模型推理 decode 阶段 | 每 step 只生成 1 token,访存大但计算少 | — | 天然 Memory-Bound;优化方向是 KV cache 压缩、PagedAttention、batching;详见 LLM 推理章节 |
"屠龙时用屠龙刀,日常吃鸡用小刀"——选模型不能只看 FLOPs,要看模型的 I 和目标平台的 Imax 是否匹配。
⑥ 常见误区
Q: Roofline 给出的是模型实际能跑出的性能吗?
不是。Roofline 给的是理论上界。实际性能还受 cache 大小、GEMM 实现质量、kernel launch 开销、调度策略、PCIe 拷贝、CPU 预处理等很多因素影响,所以实测往往低于 Roofline 上限——但永远不可能高于它。
Q: Imax 是模型的属性吗?
不是。Imax = π / β 是平台的属性,和模型无关。模型的属性是它自己的计算强度 I。判断 Compute-Bound / Memory-Bound 就是比较"模型的 I"和"平台的 Imax"。
Q: FLOPs 越小的模型在大卡上越快吗?
不一定。MobileNet 的 FLOPs 只有 VGG 的 1/30,在 1080Ti 上的实际理论性能是 3.3 TFLOP/s(卡在带宽上),而 VGG 是 11.3 TFLOP/s(吃满算力)。MobileNet 速度的真实优势只有约 10 倍,而不是 30 倍。FLOPs 不能直接外推为耗时。
Q: 训练和推理的 Roofline 一样吗?
不一样。前向传播的 FLOPs 和访存量本文已经给出。训练还要算反向传播(FLOPs 翻倍,访存量也涨)和梯度更新(Momentum、Adam 这些优化器还要存额外状态,访存量再涨),所以训练的 I 通常比推理小,更容易 Memory-Bound。
Q: Roofline 在 LLM 上还适用吗?
适用,但要分阶段看。Prefill 是大矩阵乘,I 很高,通常 Compute-Bound;Decode 每次只算 1 个 token,但要把整个 KV cache 读一遍,I 极低,通常 Memory-Bound。这就是为什么 LLM 推理的关键优化都集中在"怎么少搬 KV cache"——PagedAttention、量化、MQA/GQA 都是这个思路。
关联模块
- [
Transformer 与大模型基础 / 07-roofline-analysis](../../transformer/07-roofline-analysis.md):把 Roofline 用在 Transformer 算子分类上。 - [
Transformer / 08-decode-memory-bound](../../transformer/08-decode-memory-bound.md)、[09-operator-bound-classification](../../transformer/09-operator-bound-classification.md):LLM Decode 为何是 Memory-Bound 的具体推导。 - [
GPU / 03-performance-metrics](../../gpu/03-performance-metrics.md)、[09-bottleneck-classification](../../gpu/09-bottleneck-classification.md):从 GPU 视角看算力 / 带宽 / 利用率诊断。 - [
性能预测与建模 / 01-examples](01-examples.md):把 Roofline 这种"白盒上界"和 ML 树模型的"黑盒回归"放在一起对比,理解何时该用哪种预测方法。