内容模块
整体架构
基础★☆☆⏱ 15 min一句话结论
Transformer 的核心是用 self-attention 在序列内建立全局依赖,再用 FFN 做逐 token 非线性变换。
复习定位
| 维度 | 内容 |
|---|---|
| 所属模块 | Transformer 与大模型基础 |
| 章节类型 | 概念类 |
| 解决问题 | 围绕 Transformer 架构、输入表示、Attention、训练稳定性和面试高频题建立大模型基础答案。 |
| 面试抓手 | 先讲整体数据流,再讲每层组件和残差归一化。 |
架构图
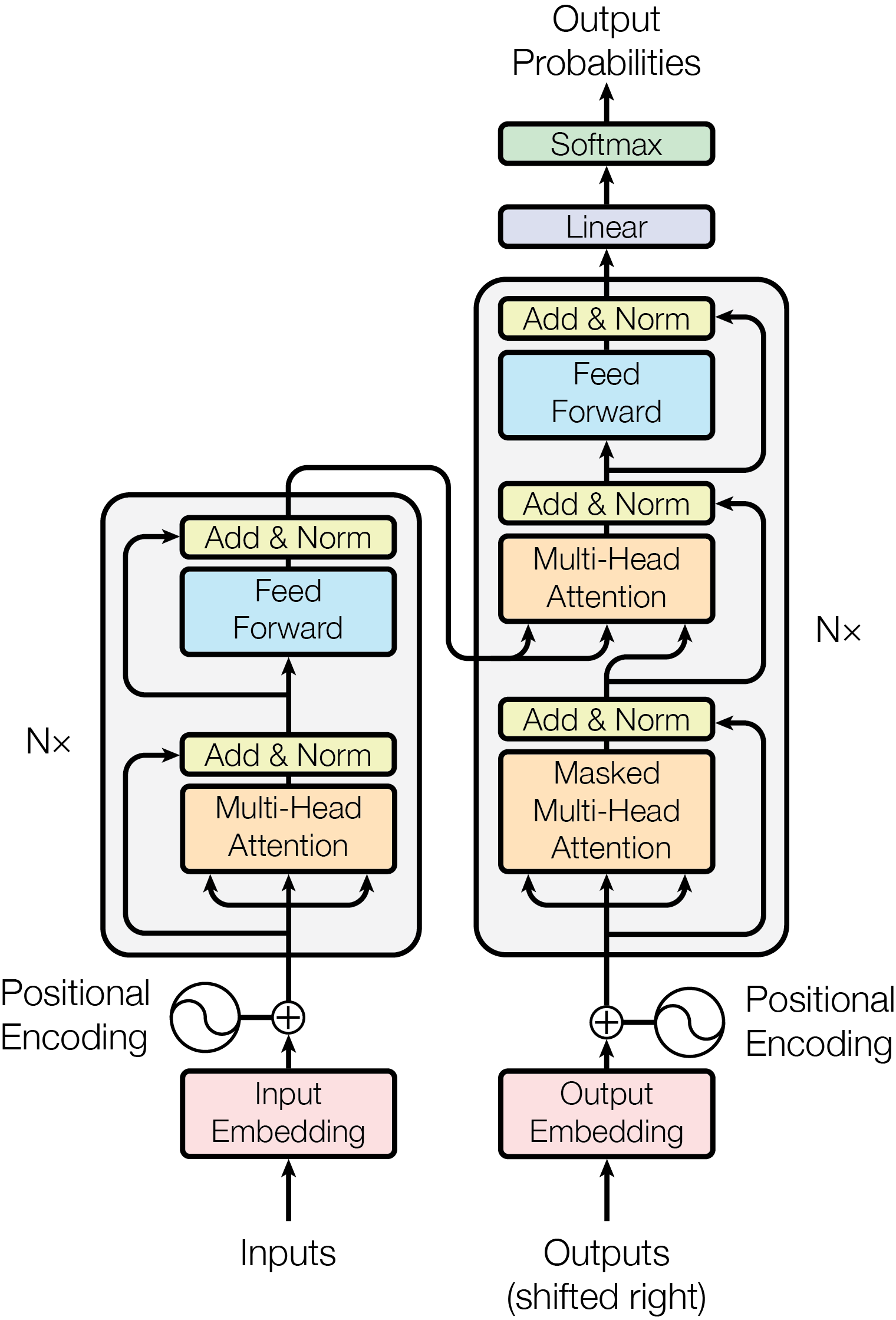
这张图是原论文的标准架构图,适合建立全局结构;后面的内容会补充现代 Decoder-only 大模型和 Pre-LN/RMSNorm 等工程变体。
核心概念
Transformer 不是一个“Attention 模块”,而是一套可堆叠的序列建模骨架。它把每个 token 表示沿着两条路径推进:
- 残差主干路径:保存并累积 token 表示,让深层网络仍然可训练。
- Attention 混合路径:让 token 之间交换信息,建立上下文依赖。
- FFN 变换路径:对每个 token 独立做非线性投影,提供容量和知识存储。
- 归一化路径:控制激活尺度,稳定训练和长层数堆叠。
系统链路
01
文本输入
tokenizer 切分成 token id
02
Embedding
token id 查表得到向量,叠加位置或旋转位置信息
03
Attention
通过 Q/K/V 让 token 间交换信息
04
Residual + Norm
保持梯度通路并稳定激活分布
05
FFN
对每个 token 独立扩维、激活、降维
06
LM Head
Decoder-only 模型投影到词表并预测下一个 token
关键机制
Encoder、Decoder 和 Decoder-only 的边界
| 架构 | 注意力可见性 | 代表模型 | 适合任务 | 系统含义 |
|---|---|---|---|---|
| Encoder-only | 双向,任意 token 可看全句 | BERT | 分类、抽取、embedding | 没有自回归 decode,推理通常一次前向完成 |
| Encoder-Decoder | Encoder 双向,Decoder 因果 + cross-attn | T5、原始 Transformer | 翻译、摘要、seq2seq | Decoder 每步还要读 Encoder memory |
| Decoder-only | 因果 mask,只能看历史 token | GPT、LLaMA | 生成、对话、代码 | 当前 LLM serving 主流,KV cache 是核心状态 |
Pre-LN 与 Post-LN
原始 Transformer 更接近 Post-LN:
$$
x_{l+1} = \operatorname{LayerNorm}(x_l + \operatorname{Sublayer}(x_l))
$$
现代大模型更常用 Pre-LN 或 RMSNorm 变体:
$$
x_{l+1} = x_l + \operatorname{Sublayer}(\operatorname{Norm}(x_l))
$$
Pre-LN 的好处是梯度主干更直接,深层训练更稳定;代价是最后通常还需要一个 final norm,并且不同实现会影响激活尺度和初始化策略。
Attention 和 FFN 的职责不同
| 模块 | 做什么 | 资源特征 | 深度理解 |
|---|---|---|---|
| Attention | token 间通信,决定“谁看谁” | prefill 有 \(O(n^2d)\),decode 读 KV cache | 更像动态路由和上下文聚合 |
| FFN / MLP | 每个 token 独立变换 | 参数量和 FLOPs 通常占大头 | 更像逐 token 的非线性记忆库 |
| Norm | 控制尺度 | 算子小但常 memory-bound | 保证深层堆叠的数值稳定 |
| Residual | 保留主干信息 | 几乎纯读写 | 提供梯度高速通道 |
深度追问
| 追问 | 回答抓手 |
|---|---|
| 为什么 Attention 本身不懂顺序? | Attention 对 token 集合是置换等变的,必须注入位置编码或 RoPE。 |
| 为什么 Decoder 需要 causal mask? | 自回归训练时不能看未来 token,否则 teacher forcing 会泄漏答案。 |
| 为什么现代 LLM 多是 Decoder-only? | 统一输入输出为 next-token prediction,训练数据形式简单,推理状态可用 KV cache 增量维护。 |
| 为什么 FFN 很重要? | 参数和计算量大,提供模型容量;很多事实知识和非线性变换能力在 FFN 中体现。 |
| 为什么 Transformer 适合 GPU? | 大部分核心算子是 GEMM/attention block,可批量并行;但 decode 阶段会转向 memory-bound。 |
关联模块
GPU 硬件与资源共享:提供硬件、显存、互联和利用率诊断基础。LLM 推理系统 / 分布式训练:提供大模型系统中的实际落点。Kubernetes / 调度与集群:提供平台、资源和多租户治理语境。专题综合题 / 论文工作:把基础知识组织成可复述的方案和项目叙事。